1.1 Introduction
Since July 2000, when the world was introduced to .NET, the IT world has been abuzz with this latest developement at Microsoft. There have been several terms that have been associated with .NET that have also been floating around, such as CLR, and IL, among others. In this session, we will be providing an overview of .NET and discussing each of these terms. In addition to this, we will also be looking at what .NET actually comprises of. This information will be essential when we work with C# and Winforms later.
To begin with, however, we shall have a look at how .NET has evolved, and where exactly it fits in.
1.2 Transformation in Computing
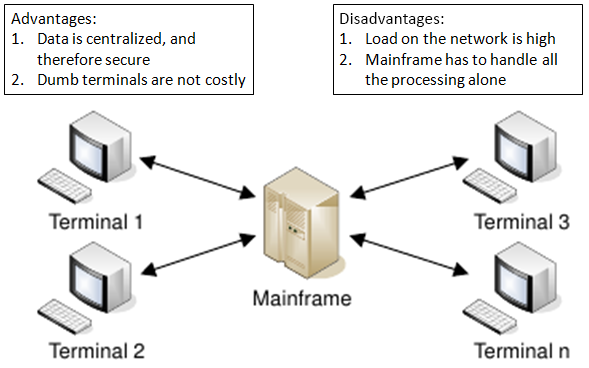
Somewhere in the beginning of the computing timeline, when the concept of networks was introduced, a mainframe sat at the head, with several dumb terminals connected to it. These dumb terminals did not possess any processing power. Therefore, all the processing was done at the mainframe’s end. The figure below illustrates this step in computing. It also lists the advantages and disadvantages of the same.
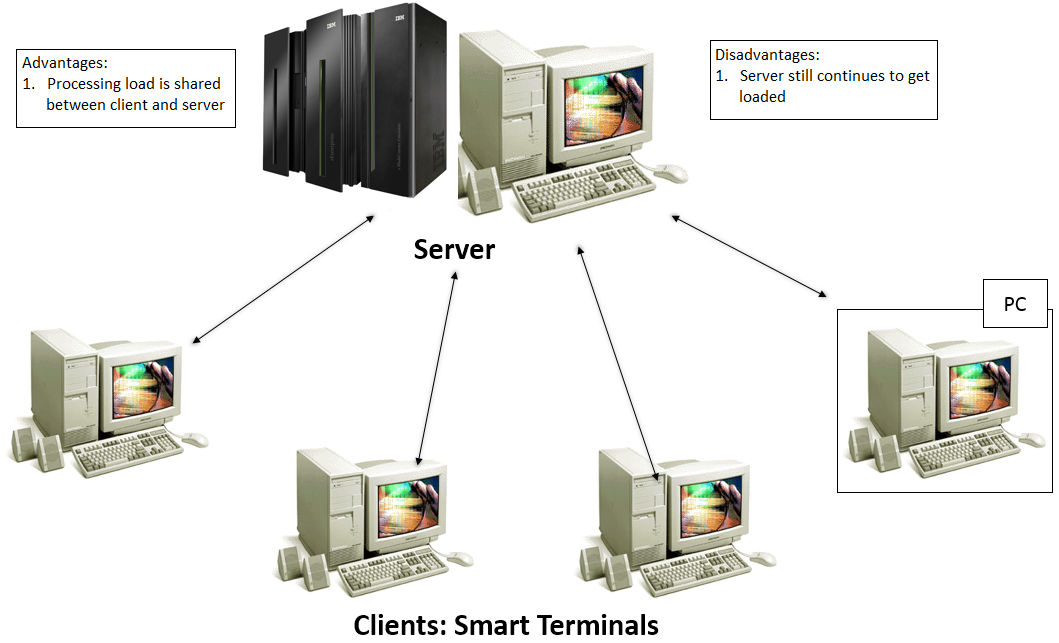
With time, the PCs gained popularity, and they became affordable as well. Therefore, a new form of computing arose, in which the dumb terminals were replaced by the intelligent PCs. This form of computing used the processing capabilities of the PC as well. The PC, therefore, became a ‘client’ that requested information from the ‘server’. Hence, client-server computing was born! This could be illustrated as shown below. Note, as shown in the figure, that the server could be a mainframe or even a high-end PC.
The advantages and disadvantages of the same are also listed in the figure.
While such a scenario reduced the load on the server, the clients still depended on the server all the same. This meant that the load on the network continued to be present. Moreover, with time, the processors became more powerful. However, their potential was not being totally utilized in such a client-server scenario. As a result, for most of the time, the processor was idle. Therefore, there was a need felt for an architecture, where the processor time would be utilized more fully, and the dependence on a server would be removed.
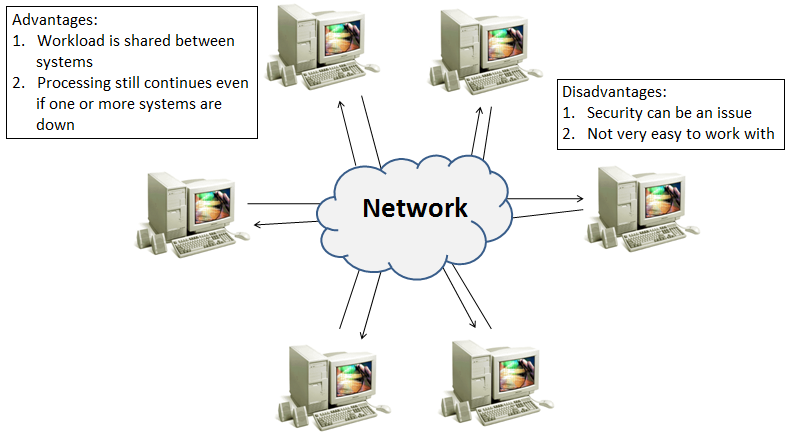
The next phase of computing, namely ‘Distributed Computing’, hence evolved out of the client-server architecture. This evolution was triggered because of the fact that the processing power of the PCs was still not being utilized to its optimum. As a result the processor was dormant most of the time. Therefore, it was assumed that if a job could be distributed between several computers, it would be done much more quickly. Such jobs could be distributed between computers in a network, so that the different computers could end up doing several jobs at the same time parallel to each other, and the workload could thus be shared. A job, therefore, that would take a supercomputer a little while to do, could be completed using such a scenario in much lesser time.
Below figure illustrates the concept of ‘Distributed Computing’, and lists the advantages as well as disadvantages of the same.
While such a scenario was popular in a local network, these days, with the popularity of the Internet, distributed computing is also being used on the Internet. SETI@home is a popular application of this concept. With more and more applications moving towards such an architecture, it looks like distributed computing is here to stay (for a while at least!).
1.3 Transformation in the Internet
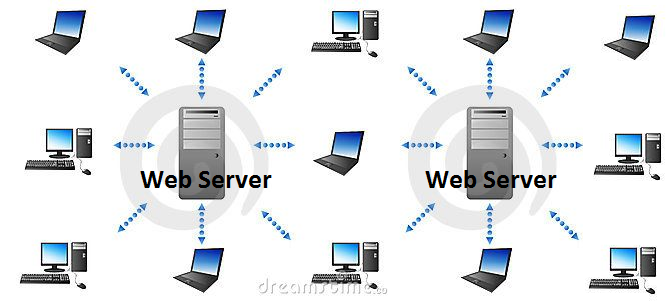
The Internet too has been evolving since its inception. Earlier (even right now, perhaps), websites used to work as islands, providing information to the clients requesting it. Figure below illustrates this. Here, mobile devices, PDAs (Personal Digital Assistants), laptops, desktop computers and other such devices access information from the web servers. However, each of the web servers from where the data is accessed exists in isolation from the other. In other words, there is no interaction between these.
In addition to this, these web servers do not send the actual data, but ‘pictures’ of data. That is, when the servers are requested for data which exists in a database, these web servers interact with the RDBMS, access the required data, embed it within HTML, and send this HTML code across to the browser. Below Figure illustrates this pictorially.
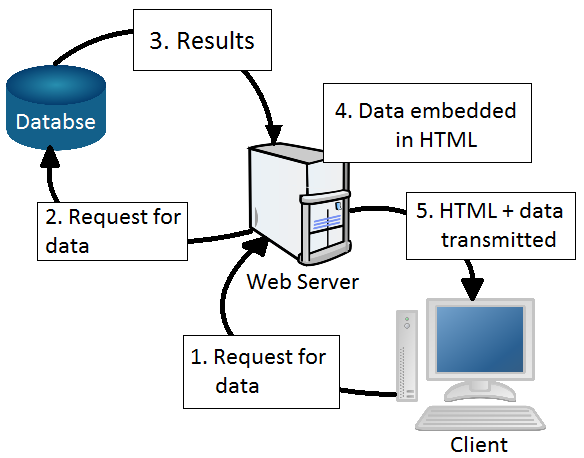
Therefore, when the data has to be sorted or filtered, the command needs to be sent again to the server, which in turn interacts with the database server, and returns the sorted or filtered data.
Again, with the varied number of devices that the user currently uses, it becomes even more difficult to provide the same information to the user through all the devices. For example, a person with a whole lot of devices may have some of them connected at home, and some in the office, and a few (such as the laptop or PDA) she would carry around with her. In such a scenario, the user may need to access the same information regardless of where she is, and which of the devices she is using. For instance, she may want to listen to the mp3 songs, which she has on her home PC, while she is in office, or she may want to access the details present in her address book of her PC, through her mobile. In other words, the user feels the need to access her data from just about anywhere, with just about any device. On the user’s part, this calls for a ‘personal information space’, where all the information can reside centrally and from where the user can access all her information. On the developer’s part, this calls for tools that help him develop just one application that runs on every device.
Therefore, as can be seen, there is a need for websites to be able to interact with each other to provide the necessary services, and information. In other words, the Internet needs to be transformed from a set of isolated islands, which provides ‘pictures’ of data, into a constellation, which provides the data itself, as well as a collaborative experience to the users who visit the sites.
1.4 Transformation in Application Development
Quite obviously, along with the transformation in computing as well as in the Internet, application development has also undergone a transformation.
A few years ago, when component technology became popular, individual components were created, which were reused by other applications. The component was built in such a way that it enclosed only the necessary functionality within it. In order to reuse this component, the developer had to ensure that it was present on the local system itself. The component exposed methods, which could be called by the application in order to invoke the required functionality. Note that the code providing the functionality itself was not exposed to the application developer. In such a scenario, the application can be referred to as a client which requests service from the component (the server).
Although such a scenario provided reusable components, which reduced the developer’s job, the drawback was that these components needed to be present locally. This limitation was reduced by newer technologies such as D-COM, RMI, and CORBA, where components could be present on the network, and their functionality accessed across it. A minor limitation, however, still persisted.
The same technology had to be used on the client, as well as the server. Therefore, if CORBA clients were used, the server needed to be CORBA-compliant. This limitation posed a problem when it came to vendor-independent component communication. For example, when a D-COM client needed to talk to a CORBA-server, a whole lot of code had to be written to make this communication possible. And coincidentally, if the server were to be replaced by an RMI-server, the code would also need to be reworked on.
This obviously meant that there was need for a transformation in the way applications were developed, so that clients and servers could communicate with each other in a vendor-independent manner. Here, therefore, we came upon the concept of web services, where components (or even entire applications) exposed their functionality over the Internet. Other applications (clients) could invoke this functionality in order to get a particular job done. These components or applications that expose their functionality are known as ‘web services’. A web service may, therefore, be invoked by another web service, or by an application. Note here that the essence of web services is vendor-independence. Therefore, a web service created using C# can be invoked by a client built using Java, and vice versa.
1.5 .NET – A result of this evolution
With the transformation in computing, it became obvious that distributed computing was here to stay. On the other hand, with the transformation in the Internet, communications and computing got melded together, with the same applications being available on devices other than computers. Moreover, web sites evolved into constellations from the isolated islands that they were. Similarly, with the transformation in application development, software is soon expected to be available as a service, and applications are expected to be available to anyone, anywhere.
Microsoft’s .NET is supposed to be aiding each of these. That is, .NET is said to fuel the next generation of computing, accelerate the next generation of the Internet, and ease the next generation of application development.
In this context, it can be said that .NET is a whole new platform centered around the Internet. With .NET, user data lives on the net. This data is accessible to the user from any place, at any time, through any .NET compatible device. It also enables the user to create applications that harness the power of the Internet. These applications are accessible via any browser, and any device.
1.6 Building .NET applications
The unique feature of .NET is the multi-language support that it provides. While Java boasted about being a language that allowed developers to develop applications that run on multiple platforms, .NET provides several languages that allow developers to develop applications that run on the Windows platform.
Earlier, in languages such as Visual Basic or C++, the source code written in the particular language is compiled by the specific compiler into the executable code. Each language has its own runtime, which takes care of executing the executable code that has been generated. This, therefore, requires the languages to have their own compilers as well as their own runtimes.
In .NET, however, the respective language’s compiler compiles the source code into an intermediate format-called the ‘Intermediate Language’ (also called IL or MSIL). This replaces the ‘Executable code’ that used to be generated earlier. Moreover, each language does not have its own runtime. Here, the language-specific runtime is replaced by a Common Language Runtime. This runtime takes care of executing the IL that has been generated. The IL and CLR will be discussed in detail in a later section.
1.7 Executing a .NET program
A program written in a language supported by .NET, is compiled by the language-specific compiler into Intermediate Language, as mentioned earlier. At the end of this compilation, therefore, we get a PE (Portable Executable) file, which contains the IL. When this program (or PE file) is executed, the CLR compiles it into machine code just before the execution. It is, therefore, said to be ‘Just in Time’ compiled, or JITed. Hence, it can be noted that a piece of source code written in a .NET language is compiled twice. The first compilation is slower than the second, as the IL generated after the first compilation is very close to machine code.
The CLR today is built for the Windows platform. This means that the machine code generated by the CLR can only he executed on the Windows platform.
